Привет всем моим читателям! Сегодняшнюю статью я посвящаю подробному рассмотрению работы с внутренними дублями страниц сайта
Оптимизации сайта – это планомерная работа, направленная на его развитие. Одним из ее компонентов является удаление из выдачи поисковых систем дублей страниц сайта.
Реклама: http://www.di-net.ru/collocation/dedicated/
Вначале давайте разберемся с негативными последствиями присутствия дублей контента. Их несколько:
• Происходит размытие внутреннего ссылочного веса. Внутренняя ссылка, призванная увеличивать значимость продвигаемых страниц, ссылается на дубли страниц и нивелирует свое предназначение.
• Случается замена релевантных страниц. Например, при продвижении карточки товара текст дублируется в категории. Поисковик может выбрать подраздел как более релевантный. Тогда пользователь попадет не прямо на товар, а в общую категорию, где искомый продукт потеряется среди других в случае значительного ассортимента. Потенциальный клиент может так и не стать реальным.
• Уникальность контента, представленного в одном документе, теряет свою ценность с каждым дублем.
Причиной появления дублей в основном являются особенности системы управления контентом(CMS). Иногда к таким последствиям приводят действия веб — мастера, копирующего тексты. Копия может быть полной или частичной.
Считается нормальным, если текст частично дублируется в пределах одного сайта порядка 10-15%. Цифра в 50% говорит о том, что пора принимать меры.
Рассмотрим соотношение реальных, полезных пользователю и поисковику, и проиндексированных страниц. Часто встречается ситуация, когда разные поисковые системы показывают разные данные по индексации. Дело в работе самого поисковика. Огромная цифра в индексации, существенно отличающаяся от количества реальных страниц, указывает на наличие дублей.
Методы поиска дублей
• Полностью проанализируйте проиндексированные документы. Анализировать придется визуально, просматривая все страницы сайта, включенные в индекс. Введите запрос site:vash-domen.ru и методично просматривайте результаты (Яндекс дает не более 1000, у Google – неопределенно).
Анализируйте URL и ищите среди них нетипичные. Для облегчения процесса можно спарсить URL, тогда смотреть на них удобнее. Поможет Yandex Parser. Полученные результаты скопируйте в любой текстовый файл или excel и ищите. Нетипичные документы лучше запретить к индексации.
Для Google я альтернативы не нашел. Пока не нашел.
• Проверяйте внутренние ссылки, создающие дублированные страницы. Существуют CMS, которые создают дубли документов с помощью внутренних ссылок, то есть ссылаются не на основной материал, а на дубль. Такие ссылки надо удалять или переделывать в адекватные.
Проверять ссылки можно самому или употребить специальный софт. Программа Xenu ищет битые (нерабочие) ссылки на сайте. Она проста в использовании, хоть и на английском.
Скачайте Xenu и установите ее на компьютер. Запустив, выберите в меню File -> Check URL. Затем заполните первое поле, внеся в него адрес своего ресурса , нажмите “ОК”. Программа будет ходить по ссылкам и отмечать нерабочие, рабочие, внешние, внутренние, заголовки и description. Время работы программы зависит от объема ресурса.
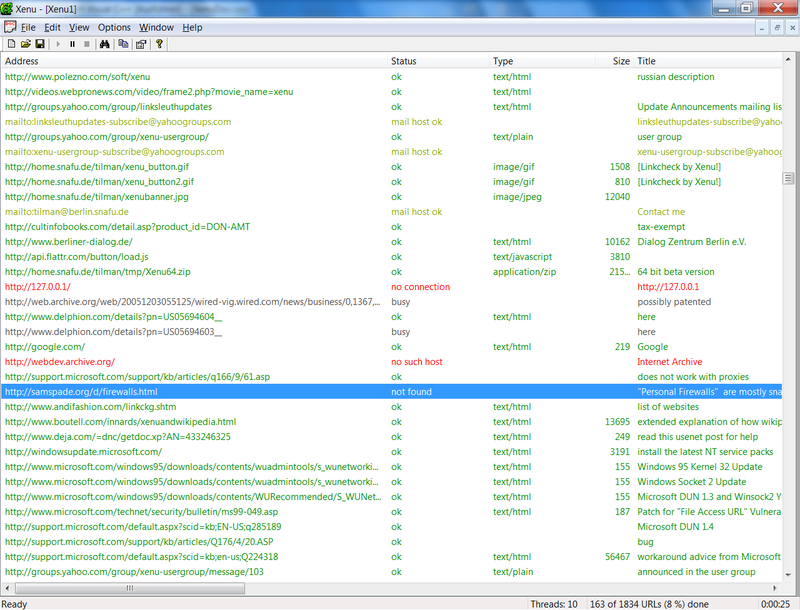
После завершения работы программа предложит создать карту сайта и залить ее по ftp. Это делать не обязательно. Сохраните результаты в каком-либо текстовом файле или в Excel: File -> Export to TAB separated file. Так легче производить анализ.
• Дубли можно искать по кусочкам текста. Эта вполне стандартная процедура заключается в том, чтобы любой кусок текста документа заключить в кавычки и искать через поисковик. Желательно таким образом проверить не менее 10 документов из каждого подраздела сайта.
• Google Webmaster. Если ваш проект добавлен в этот ресурс, то вы можете получить полезную информацию по индексации ресурса. Зайдите в “Оптимизация -> Оптимизация HTML”. Там есть данные по дублирующимся мета — описаниям (description) и заголовкам (title).

Часто повторы в этих тегах сигнализируют о наличии дублей контента. К сожалению, стандартные методы в данном случае не спасают.
• Метод, схожий с описанным выше поиском по кусочкам текста. Но здесь поиск осуществляется в заголовках (тег title) и в адресах URL документа. У дублей эти элементы схожи.
Как избавиться от дублей?
Существует несколько методов удаления дублей сайта из выдачи поисковой системы. Ваша задача – решить, в каких случаях подойдет один из них, а в каких поможет только комплексный подход.
• Удаление вручную. Если дублирующая статья или html-страничка создавалась вручную, то и удалить ее можно также.
• 301-редирект. Стандартная процедура склеивания абсолютно идентичных документов.
• Атрибут rel=”canonical” сейчас понимают основные поисковые системы — Google и Яндекс. Он дает поисковому роботу информацию о странице, предпочитаемой множеству схожих по содержанию. Например, интернет-магазин в категории кухонных плит предоставляет несколько сортировок: по цене, популярности, дате добавления, и тп. Чтобы среди подобных документов поисковик выбрал главную страницу в качестве канонической, нужно указать представленный атрибут для всех копий. Современные движки (WordPress) включают данный атрибут в структуру создания документов.
• Файл robots.txt запрещает поисковому роботу индексировать указанное содержание ресурса. Главное, найти стандартный robots.txt для вашей CMS. Как правило, он ограждает сайт от индексирования документов, дублирующих содержание.